How Did DeepSeek Catch Up at a Fraction of the Cost?
Like everyone else, I was more than a little surprised by Deep Seek. I’d been plugging along using the other models and tools for artificial intelligence writing, planning, and crafting. I also still think the best writing tool is my brain and my hands, but there you have it.
Still, I teach and explore the world of AI and was fascinated by what just happened in the world of Large Language Models and the boom-snap of Deep Seek and its ability to tank the Nvidia market overnight. So, as one of the limited pool of tech writers paying attention to how these things take place, I figured I’d give a brief explanation and share a few thoughts here, with a nod to the folks who taught me a thing or two along the way.
DeepSeek’s leap comes down to four major innovations (and some smaller ones). Here’s the lowdown:
They distilled from a Leading Model, for starters DeepSeek likely distilled its model from an existing one—most likely Meta’s Llama 3, though they could have accessed OpenAI’s GPT-4 or Anthropic’s Claude. Distillation involves training a new model using an existing one, much like OpenAI’s GPT-4 Turbo, which provides solid performance at lower costs by leveraging GPT-4 as a teacher. This approach slashes the time and cost of creating a training set, but it has limits. Since your starting point is always someone else’s previous release, leapfrogging the competition becomes far more challenging. If DeepSeek used OpenAI or Anthropic’s models, it would violate their terms of service—but proving that is notoriously difficult.
Inference via Cache Compression DeepSeek slashed the cost of inference (the process of generating its responses) by compressing the cache that the model uses to make predictions. This breakthrough was clever but it wasn’t entirely unexpected. It’s a technique that others probably would have figured out pretty soon. More importantly, DeepSeek published the method openly, so now the entire industry can benefit from their efforts.
Mixture of Experts Architecture Unlike traditional LLMs, which load the entire model during training and inference, DeepSeek adopted a “Mixture of Experts” approach. This uses a guided predictive algorithm to activate only the necessary parts of the model for specific tasks. DeepSeek needs 95% fewer GPUs than Meta because, for each token, they train only 5% of the parameters. This innovation radically lowers costs and makes the model far more efficient.Cheaper
Reasoning Model Without Human Supervision DeepSeek didn’t just match leading LLMs like OpenAI’s GPT-4 in raw capability; they also developed a reasoning model on par with OpenAI’s o1. Reasoning models combine LLMs with techniques like CoT, enabling them to correct errors and make logical inferences—qualities predictive models lack. OpenAI’s approach relied on reinforcement learning guided by human feedback. DeepSeek trained their model on math, code, and logic problems, using two reward functions—one for correct answers and one for answers with a clear thought process. Instead of supervising every step, they encouraged the model to try multiple approaches and grade itself. This method allowed the model to develop reasoning capabilities independently.
The TL;DR
Innovation Beats Regulation DeepSeek’s success is a reminder that competition should focus on technological progress, not regulatory barriers. Innovation wins.
Lower Costs All Around DeepSeek’s architecture dramatically reduces the cost of running advanced AI models—in both dollars and energy consumption. Their open-source, permissively licensed approach means the whole industry, including competitors, benefits.
Models Are Becoming Commodities As models become cheaper and more widely available, the value will shift toward building smarter applications rather than simply integrating a flashy “AI button.” Product managers who can creatively apply AI will drive the next wave of real-world impact.
NVIDIA’s Moat Is Shrinking DeepSeek’s GPU efficiency challenges assumptions about NVIDIA’s dominance. If others adopt similar techniques, the grip of chipmakers on the AI economy may loosen significantly.
*For some DeepSeek FAQs from folks who know a lot more than me, go here.
We’re a few weeks into 2024 and now that we’re past the “best of” lists and the “year in review” lists, there’s a bit of time to take a look at what we might find most productive in the coming quarters. I always enjoy taking a few deep breaths once the frenzy of the year-start fades to look at what I might find truly useful as the daffodils peek their heads up in the park and I begin to feel the true momentum of the year take shape. I kick off the winter blues and roll my sleeves up to dig in.
This year, my company is more sure than ever that we will harness the ever-growing powers of AI as it enters a more mature phase, and I for one am grateful for the embracing of that stance. Artificial Intelligence, especially generative AI, is no longer just a buzzword. Companies are beginning to sift through the hype to discover what is really providing value and what was just marketing hubris. I’m glad of it. I suppose I am glad because I work for a company that knows the difference and tends to put their weight behind it. Sure, we have some applications that are neither artificial nor intelligent, but we own up to the ones that are data and machine learning, and we boast about the ones that have weight to throw around. And that is fun and ambitious.
So I enjoy rolling up my sleeves to explore the ways that Generative AI might improve my work, and I enjoy tossing out the ways that it is a big, fat dud. So let’s look at the four ways I think it might actually improve what I do.
Drafting
First drafts are the things that take up the bulk of any writer’s time, whether tech writer or fiction writer. We know what it is that we want to say, we just aren’t sure how to get started. It’s not writer’s block per se, it’s just the words in our brains don’t spill out on to the page as quickly as we’d like or as smoothly as they should. Our years of training are well suited to editing and refining, which we are likely to have already begun in our heads. It’s the typing that can be painful because it simply isn’t as fast as our thought processes.
But a Generative AI tool is as fast. Faster, even. If we can spin up a good prompt, we can get some of the process started, and that is often enough to grease the wheels and we can take it from there.
Most likely the way we will be able to effectively harness what Gen AI really has to offer is to become adept at crafting and refining the prompts to get us started. I began writing chapters of my book recently by asking ChatGPT to help me organize the table of contents, then I asked it to revise that TOC because it wasn’t quite the way I liked it. The actual TOC looks nothing like it did when good ol’ AI first started it, but what was nice is that it gave me liftoff. I knew in my head what I wanted to do, but the way my creative brain was working was to think of the book as the whole, not its parts. That is awful for a writer. As the saying goes, “you can’t boil the ocean.” Indeed you can’t. And while AI wrote not a single word of this post, that’s because I have been able to think of its component parts. With my book, I was thinking of the whole thing, start to finish, and I needed a hand in visualizing what the chapters might look like. By asking AI to help me out with that, I was able to think of the pieces rather than the whole. It was only then that I could sit down and begin to write.
With that in mind, we as creators will be able to ask Gen AI not to write for us, but to draft for us, so that we can get out of the muck that is stuck in our brains and begin to refine and edit and revise after the foundation is laid. What is left behind as detritus will be much like what we left behind us when we were drafting ourselves – an unrecognizable skeleton of tossed aside word salads. It requires our fine touch to render the work useful and beautiful. Gen AI will have helped us get there faster, much the same way moving from horse to car allowed us to move from place to place more quickly, too.
Automating Q&A
As a tech writer, I cannot even begin to tell you how many times I have been asked to write an FAQ section for documentation.
My answer to this request is always the same. I will not.
I will not write an FAQ because if there are frequently asked questions, I should answer those within the documentation. Sheesh!
And yet.
There remain some questions that indeed, users will face time and again that are unlikely to be answered in the documentation. I get it. No matter how much of a purist I am, I understand that there are frequently asked questions that need frequent answers.
So a technical writer can collate those questions and help develop the chatbot that integrates with a product’s or company’s knowledge repository to answer those repetitive questions effectively. This bot can instantly provide responses in a way that no live writer could, through a call-and-response mechanism that is smoother than static documentation. By leveraging AI, we can ask our tools to ingest data and interpret our users’ needs and provide output that is both relevant and accurate. This can enhance the user’s experience by responding immediately whereas a human might require time to look something up, or might be off-hours or otherwise detained.
AI-powered chatbots are efficient, interactive, and fast. But they serve only after technical writers feed them all they need in terms of information. It’s vital to remember that our AI tools are only as good as the data they are given to start with.
Data
Technical writers will also be very well served by the data that AI can give us. Back when I was in graduate school, we worked very hard to manually enter volumes of information to build dictionaries of strings of phrases and what they meant in general syntax. It was difficult and time consuming. Today, though, thanks to AI-powered tools, we could have completed that project in a fraction of the time.
How AI data will benefit tech writers is that it will allow us to gather truly valuable insights into our users’ behaviors and we can stop making what we once knew were educated guesses about their pathways. Tools we have now measure user engagement, search pattern behaviors, and even the effectiveness of our content through click rates, bounce patterns, andmore, and they serve it all up in nice, tidy numbers. We can use this to optimize our content and identify the gaps we see and close them quickly.
Leveraging analytics data allows tech writers now to focus on the content our users access often, the content that interests them the most, and the keywords they search – and do or do not find – with greatest success. Plus, we can now see just what stymies our users and all of this will empower us to create the most targeted content that will greatly improve the user experience.
Optimization
More than just a buzzword, content optimization is probably the most powerful benefit of AI-enabled tech writing. Asking a good AI tool to analyze technical documentation to provide feedback about readability against a style guide and structural rules is probably the best thing we could ask for. Sure, we’ve got things like grammarly and acrolinx to do spot-checking. That’s all well and good. But now AI can help us enhance accessibility, it can help us tailor content for specific audiences, it can allow or disallow entire phrases and terms. We can advance our proofreading capabilities far more than we could before by loading in custom dictionaries and guides.
Tools like grammarly are basic, but with advancing NLP processing tools, the arsenal we have just grows. We can pass our work through a domain-specific tool that offers a profession-specific set of guidelines and lets us examine with a microscope things like acronyms, codes, and more.
The time savings there is not perfect, of course. We’ll still need to copyedit. But imagine, if you will, that every first or second pass of all of our text now is done in mere seconds. All typos are caught by AI so that we can clean up and polish with an editor’s eye not just a proofreader’s.
Sit back with a cup of coffee and really read, not just grab a pencil and mark up a piece of paper the way we used to.
We are all well aware that AI is the hottest topic everywhere. You couldn’t turn around in 2023 without hearing someone talk about it, even if they didn’t know what the heck it was, or is. People were excited, or afraid, or some healthy combination of both.
From developers and engineers to kids and grandmas, everyone wanted to know a thing or two about AI and what it can or cannot do. In my line of work, people were either certain it would take away all of our jobs or certain that it was the pathway to thousands of new jobs.
Naturally I can’t say for certain what the future holds for us as tech writers, but I can say this – we as human beings are awful at predicting what new technologies can do. We nearly always get it wrong.
When the television first arrived, there were far more who claimed it was a fad than those who thought it would become a staple of our lives. The general consensus was that it was a mere flash in the pan, and it would never last more than a few years. People simply couldn’t believe that a square that brought images into our homes would become a thing that eventually brought those images to us in every room of our homes, twenty four hours a day, offering news and entertainment, delivering everything we needed all day and all night. They couldn’t fathom that televisions would be so crystal clear and so inexpensive that every holiday season the purchase of a bigger, better, flatter, thinner television would be a mere afterthought.
And yet here we are.
So now that we’ve got that out of the way, on to total world domination!
But seriously.
If you aren’t already using AI, or at least Gen AI in the form of something like Chat GPT, where are you, even? At least have a little play around with the thing. Ask it to write a haiku. Let it make an outline for your next presentation. Geez, it’s not the enemy.
In fact, it’s so much not the enemy that it can help you outline your book (like I’ve done), revise a paragraph (like I’ve done), or tweak your speech (like I have done many, many times). The only thing you really need to understand here is that you are, indeed, smarter than the LLM. Well, mostly.
The LLM, or large language model, does have access to a significantly grander corpus of text than you can recall at any given moment. That’s why you are less likely to win on Jeopardy than if you were to compete against it. It’s also why it might be true that an LLM competitor might make some stuff up, or fill in some fuzzy details if you ask it to write a cute story about your uncle Jeffrey for the annual Holiday story-off. (What? Your family does not actually have an annual story-off? Well, get crackin’ because those are truly fun times…fun times…). The LLM knows nothing specific about your uncle Jeffrey, but does know a fair bit about, say, the functioning of a carburetor if you need to draft a paragraph about that.
The very, very human part is that you must have expertise in how to “tune” the prompt you offer to the LLM in the first place. And the second place. And the third place!
Prompt tuning is a technique that allows you to adapt LLMs to new tasks by training a small number of parameters. The prompt text is added to guide the LLM towards the output you want, and has gained quite a lot of attention in the LLM world because it is both efficient and flexible. So let’s talk more specifically about what it is, and what it does.
Prompt tuning offers a more efficient approach when compared to fine tuning entirety of the LLM. This results in faster adaptation as you move along. Second, it’s flexible in that you can apply tuning to a wide variety of tasks including NLP (natural language processing), image classification, and even generating code. With prompt tuning, you can inspect the parameters of your prompt to better understand how the LLM is guided towards the intended outputs. This helps us to understand how the model is making decisions along the path.
The biggest obstacle when getting started is probably designing an effective prompt at the outset. To design an effective prompt, it is vital to consider the context and structure of the language in the first place. You must imagine a plethora of considerations before just plugging in a prompt willy-nilly, hoping to cover a lot of territory. Writing an overly complex prompt in hopes of winnowing it down later might seem like a good idea, but in reality what you’ll get is a lot of confusion, resulting in more work for yourself and less efficiency for the LLM.
For example, if you work for a dress designer that creates clothing for petite women and you want to gather specific insights about waist size, but don’t want irrelevant details like shoulder width or arm length and competing companies, you might try writing a prompt to gather information. The challenge is to write a broad enough prompt, asking the AI model for information about your focus area (petite dresses), while filtering out information that is unrelated and avoiding details about competitors in the field.
Good Prompt/Bad Prompt
Bad prompt: “Tell me everything about petite women’s dresses, sizes 0 through 6, 4 feet tall to 5 feet 4 inches, 95 lbs to 125 lbs, slender build by American and European designers, and their products XYZ, made in ABC countries from X and Y materials.”
This prompt covers too many facets and is too long and complex for the model to return valuable information or to handle efficiently. IT may not understand the nuances with so many variables.
A better prompt: “Give me insights about petite women’s dresses. Focus on sizes 0 to 6, thin body, without focusing on specific designers or fabrics.”
In the latter example, you are concise and explicit, while requesting information about your area of interest, setting clear boundaries (no focus on designers or fabrics), and making it easier for the model to filter.
Even with the second prompt, there is the risk of something called “overfitting,” which is too large or too specific. This will lead you to refine the prompt to add or remove detail. Overfitting can lead to generalization or added detail, depending on which direction you need to modify.
You can begin a prompt tune with something like “Tell me about petite dresses. Provide information about sizes and fit.” It is then possible to add levels of detail that the LLM may add so that you can refine the parameters as the LLM learns the context you seek.
For example, “Tell me about petite dresses and their common characteristics.” This allows you to scale the prompt to understand the training data available, its accuracy, and to efficiently adapt your prompt without risking hallucination.
Overcoming Tuning Challenges
Although it can seem complex to train a model this way, it gets easier and easier. Trust me on this. There are a few simple steps to follow, and you’ll get there in no time.
Identify the primary request. What is the most important piece of information you need from the model?
Break it into small bites. If your initial prompt contains multiple parts or requests, break it into smaller components. Each of those components should address only one specific task.
Prioritize. Identify which pieces of information are most important and which are secondary. Focus on the essential details in the primary prompt.
Clarity is key. Avoid jargon or ambiguity, and definitely avoid overly technical language.
As Strunk and White say, “omit needless words.” Any unnecessary context is just that – unnecessary.
Avoid double negatives. Complex negations confuse the model. Use positive language to say what you want.
Specify constraints. If you have specific constraints, such as avoiding certain references, state those clearly in the prompt.
Human-test. Ask a person to see if what you wrote is clear. We can get pretty myopic about these things!
The TL;DR
Prompt tuning is all about making LLMs behave better on specific tasks. Creating soft prompts to interact with them is the starting point to what will be an evolving process and quickly teaching them to adapt and learn, which is what we want overall. The point of AI is to eliminate redundancies to allow us, the humans, to perform the tasks we enjoy and to be truly creative.
Prompt tuning is not without its challenges and limitations, as with anything. I could get into the really deep stuff here, but this is a blog with a beer pun in it, so I just won’t. Generally speaking (and that is what I do here), prompt tuning is a very powerful tool to improve the performance of LLMs on very specific (not general) tasks. We need to be aware of the challenges associated with it, like the hill we climb with interpretability, and the reality that organizations that need to fine-tune a whole lot should probably look deeply at vector databases and pipelines. That, my friends, I will leave to folks far smarter than I.
Google has for quite some time now been the de facto word in all things web. Sure, Microsoft and Bing gave it a shot, but never quite broke through the hefty barriers set by behemoth Google. So when the folks at Google set out to put some guardrails around AI generated content, the world paid attention.
Google wrote search guidance about AI-generated content, focusing on ‘appropriateness’ rather than attribution. Their stance is that automation has long been used to generate content, and that AI can in fact assist in appreciable ways. One of the most interesting bits about their policy is noting that it isn’t just some bot that can create propaganda or distribute misinformation. In fact, they are quick to point out the very human-ness in that capability. Since the beginning of information dissemination there’s been the capacity to distribute falsehood, after all.
Further, Google asserts that AI-generated content is given no search privilege over any other generated content. And yet, despite this assertion, we know that AI tools can be asked via well-designed queries to write content that is specifically designed to tick all of the SEO boxes, thus potentially rocketing it upward in search efforts. The human brain cannot log and file all of the best potential search terms. We just don’t have that sort of computing power. But AI does. And it has it in spades.
Creating relevant, easily findable content is the whole effort for tech writers. Our jobs depend on being able to place the content users need where the content consumers expect to find it. Many of us have trained for years to scratch the surface of this need, and most of us continue to refine that ability by monitoring our users’ journeys and mapping their pathways. But now AI can do this at a speed we never could. We rely on analytics to tell us what to write where.
Moreover, as humans we rely on our own inherent creativity to design engaging and timely documentation. Every single writer I have ever known, including myself of course, has experienced a degree of “writer’s block,” sometimes even when the prompt is clear and direct. It’s tough to just get started. But when a program has access to all of the ideas ever written (more or less), that block is easy to dismantle. But when we rely on AI to generate the basis for our content, even if we intend to polish, edit, and curate that content, where does the authorship belong? Is it ‘appropriate use’ to place an author byline as the sole creator if a large language model is the genesis of the work? Google’s guidance is merely to “make clear to readers when AI is part of the content creation process.” Their clarification is…unclear.
Google does recommend, in it appropriate use guidance, to remain focused on the ‘why’ more than the ‘how.’ What is it that we, as content generators, are trying to achieve in our writing? We go back to the audience and purpose more than the mechanics and we’ll be fine. Staying in tune with the reason or reasons for our writing will keep us in line with all appropriate use guidelines. For now. If we are writing merely for clicks or views, we’ve lost our way. If we continue to write for user ease and edification, well okay then.
Even Google acknowledges that Trust is at the epicenter of their E-E-A-T guidelines (experience, expertise, authoritativeness, and trustworthiness) which is the basis of their relevant content rankings. AI could certainly create content with a high level of expertise, noticeable experience, and authoritativeness, but we’ve found that the trustworthiness is suspect.
For now, our ‘Appropriate Use’ likely remains in the domain of those of us with conscience, which AI notably lacks. Avoiding content created merely for top rankings still nets humans, and human readers, the desired end result, even if it doesn’t make the top of the list.
A 2017 article in the Washington Post discussed how now, in the age of big data and STEM (Science, Technology, Engineering, and Mathematics), liberal arts and humanities degrees are perceived as far less valuable in the marketplace. I saw the same opinion held strong at both universities where I taught English. Many, many students believed wholeheartedly that the only thing they could do with a degree in English is teach.
I was hard-pressed to convince them otherwise since I was, in fact, teaching.
The Post article goes on to argue, however, for abundant evidence that humanities and liberal arts degrees are far from useless.
When I started graduate school in 2007 at university that beautifully balances the arts and sciences (shout out to you, Carnegie Mellon!), my advisor recommended I take “the Rhetoric of Science.” I meekly informed her that I wasn’t really into science. I thought it would be a bad fit, that I would not fare well and my resulting grade would reveal my lack of interest. She pressed, saying there was a great deal to learn in the class and that it wasn’t “scienc-ey.”
She was absolutely right. I was fascinated from the start. The course focused on science as argument, science as rebuttal, but most of all science as persuasive tool. Or, at least the persuasiveness came from how we talk and write about science. My seminar paper, one of which I remain proud, was titled: “The Slut Shot. Girls, Gardasil, and Godliness.” I got an A in the class, but more importantly I learned the fortified connection between language and science.
The National Academies of Sciences, Engineering, and Medicine urges a return to a broader conception of how to prepare students for a career in STEM. Arguing that the hyper-focus on specialization in college curricula is doing more harm than good, they argue that broad-based knowledge and examination of the humanities leads to better scientist. There is certainly the goal among academics to make students more employable upon graduation, and yet there is consensus that exposure to humanities is a net benefit.
The challenge is that there’s no data. Or, limited data anyway. The value of an Art History course or a Poetry Workshop at university is hard to measure against the quantifiable exam scores often produced in a Chemistry or Statistics class.
In a weak economy, it’s easy to point to certifications and licenses over the emotional intelligence gained by reading Fitzgerald or Dickinson. We find, though, that students (and later employees) who rely wholly on the confidence that science and technology provide answers, viewing it with an uncritical belief that solutions to all things lie in the technology – well, those beliefs are coming up short. Adherence to the power of science as the ultimate truth provides little guidance in the realm of real-world experiences.
In short, not all problems are tidy ones.
After all, being able to communicate scientific findings is the icing on the cake. We don’t get very far if we have results but do not know how to evangelize them.
In American universities right now, fewer than 5% of students major in the humanities. We’ve told them that’s no way to get a job. The more we learn about Sophocles, Plato, Kant, Freud, Welty, and others, the more prepared we are to take on life’s (and work’s) greatest challenges. It is precisely because the humanities are subversive that we need to keep them at the heart of the curriculum. Philosophical, literary, and even spiritual works are what pick at the underpinnings of every political, technological, and scientific belief.
While science clarifies and distills and teaches us a great deal about ourselves, the humanities remind us how easily we are fooled by science. The humanities remind us that although we are all humans, humans are each unique. Humans are unpredictable. Science is about answers and the humanities are about questions. Science is the what and the humanities are the why.
If we do our jobs well in the humanities, we will have generations to come of thinkers who question science, technology, engineering, and math.
And that is as it should be.
I welcome discussion about this or any other topic. I am happy to engage via comment or reply. Thanks for reading.
The whole field of technical writing, or professional writing, seems to have expanded like a giant infinite balloon in the last decade. Where previously it was a specialty, now it’s an entire field complete with sub-specializations.
How cool is that?!
I told the story just the other day that when I graduated from high school, I knew I was off to college to major in English. It had always been my best subject, I love reading but I love writing more, and it was just the obvious choice. Except…I also asked for money instead of gifts because I was determined to buy my own computer. Other than some desktop publishing, I couldn’t envision what the two had in common, but I was connecting them somehow.
Had I only known then that I would spend my career as a technical writer, I probably would have gotten a much earlier start. I focused on essays and creative nonfiction, which I later taught until I discovered what I solidly believe is the best professional writing graduate program anywhere – at Carnegie Mellon. Indeed, the robotics and engineering monolith hosts an impressive writing program for students looking at Literary and Cultural Studies, Professional & Technical Writing, and Rhetoric. I opted for the last of the three and am happy with my choice, even though I landed a career in Prof & Tech.
Evangelizing this field is easy for me, even as it becomes more complicated. I can see clearly now that taking an Apple IIGS to college was the harbinger that I would eventually be a software writer. I work now for a major software company and love what I do.
But wait – there’s more. (Please say that in an infomercial voice. You won’t be sorry.)
I wrote proposals for federal-level contracts for a while. I taught Human-Computer Interaction. I edited science articles. The breadth of writing is not unique to me, and it was very helpful.
Because the company I work for delivers software solutions for medical clinical trials. Eureka! Again, that college freshman had zero idea that she could combine a love of writing, and interest in computers, and a genuine interest in science. Back then, the marriage of all three seemed impossible.
And yet…
As a technical writer starting out, it’s perhaps not so important to “find focus” in a given industry. However, once you decide you indeed want to produce professional documentation, specializing in an interest is helpful. There are so many areas to choose from that it’s nearly impossible to NOT find one that is interesting as well as challenging. I would not, for example, find deep satisfaction in writing installation manuals for gas pipelines. But someone does. Someone enjoys that very much. I participated in a review panel for a writing competition and my assigned document was an infant incubator (baby warmer) user manual to be read by nurses. I found the content to be expertly delivered, and yet I had no actual interest in what the device does or how to use it. Give me something about gene therapy research and predictive modeling? I am IN!
Some writers find that they are fascinated by banking, taxes, estate planning and so on – welcome to tech writing for loads and loads of financial applications from Turbo Tax to Betterment. The field is growing so rapidly that every investment tool, firm, and product needs a skilled writer. For those who find dollars and cents and amortization and net worth interesting it’s a huge category, and you can specialize in all sorts of ways. Someone who digs marketing but doesn’t want to be a marketer will find a spot in a real estate app, a travel tool, or even music software like iTunes. They all need documentation. Every. Single. One.
What about the folks who say the documentation is superfluous? While it may be true that an app like iTunes or Netflix is so intuitive that it doesn’t need user doc, the moment a user is stymied and needs an answer, that documentation is one thousand percent necessary.
I often talked with my students about the wide variety of uses for their writing skills, many of which would leave plenty of time for creating poetry, fiction, and the like. Heck, even I write memoir in my spare time.
But it’s Sci-tech, Med-tech, and Bio-tech that butter my bread. If you find any area that interests you, I can guarantee there’s a technical document somewhere for you to write and edit, and it’s all about that field.
There is such a swirl of discussion around Artificial Intelligence and whether it will supplant human work. This largely stems from a real misunderstanding of what AI is and what it can do. According to IBM, Artificial Intelligence is: “the science and engineering of making intelligent machines, especially intelligent computer programs. It is related to the similar task of using computers to understand human intelligence, but AI does not have to confine itself to methods that are biologically observable.”
There’s a lot packed into that definition. No wonder people don’t know quite what to make of it!
It seems to me that the biggest challenge is that people mistake Intelligence for Sentience. While humans certainly possess both, it’s not even a realistic goal in some ways to presume that we can master Artificial Sentience.
What do I mean by this?
In a nutshell, “sentience is the ability to feel, sense or experience perceptions subjectively. Those working in the field believe that capability to be decades away, if achievable at all. Building self-awareness into a machine is an unlikely undertaking, anyway. To reach that state, researchers would have to build programs that achieve generalized intelligence, a single learning machine with the ability to problem solve, recognize environments and changing requirements, and the capacity to learn more. Once that capacity is established, the next step is just reaching the edges of the potential ability to learn consciousness.
Therein lies the rub. A machine is unlikely to “learn” how to “feel,” since the uniquely human capability of complex emotions is perhaps the ultimately most difficult thing to teach. Just as a machine has no conception of physical pain or healing, the ability to feel attachment or loss is not necessarily a programmable skill.
No one in the field claims that a Roomba has any particular attachment to the floors it vacuums, despite the fact that it does indeed learn what the obstacles to successful vacuuming are. No one believes that a robot vacuum enjoys the sensation of a 120-volt charge running through its wires, even if we imagine those wires to function much like veins.
Robots still can’t feel.
Robots can mimic, absolutely. They are fantastic at aping what humans do, if they are taught to do so. Within series after series of If/Then statements, a computer can perform all sorts of functions. My robot vacuum “understands” that If there is a chair leg in the way, it should rotate 30 degrees and try again. If the block is still there, it will rotate again an again until it is able to move past the obstacle. With the most recent robot vacuums (to stick with this example), the vacuum “knows” that the chair is there and “learns” to avoid it, unless it arrives at that obstacle and finds it has been moved. That said, the vacuum is not frustrated by the obstacle, nor is it relieved when the chair is moved to another room.
I think of it often as similar to what I learned in my first college linguistics course: animals can communicate, but they do not have language. That is, my dog can let me know when he is happy, but he cannot tell me that his father was poor but honest. Machines can learn, but the challenge is that they cannot emote. They can mirror emotion, sure, but to have original and unique feelings about their situations? No. At least not yet, and not for the conceivable immediate future.
But that does not mean that machines cannot learn. They very much can. Just as a third grader can sit quietly, ingesting information and retaining it for future reference, a machine can do the same. A student learning multiplication tables soon learns that 5 x anything can only result in a number ending in 5 or 0. A machine has the capacity to learn and retain that information and apply it to millions of situations, millions of times faster than the human mind can do. A machine can aggregate vocabularies, numerical sets, geographic data, and more – all at a rate far more effectively and efficiently than the human brain.
That’s why machine learning and artificial intelligence are thrilling and fantastic.
But until that computer program can harness things like anticipation (that the car in the next lane is looking like it will merge into yours), or fear (that the spider crawling up the side has the potential to cause damage), and responds accordingly, our jobs are all safe. Machines can certainly learn to edge over if a car is too close or to restart if an interloper is nearby, but it does not have the capacity for self-awareness.
We mustn’t confuse intelligence with sentience, and if we do that, we’ll soon welcome the advancements of AI and machine learning, harnessing them for what they are.
But remember, too, that until the machine can understand notions like initiative, relaxation, and joy, it remains a tool for us to use. And remember, too, that it may well be the mindless robots may be our biggest threat, not the ones that could one day feel and thus bring us things like helpfulness, empathy, and emotional support.
Susan is a technical content strategist and researcher of all things automated. She lives in Baltimore with her two dogs and snuggles with them when she’s not on her bike or swimming laps in the pool. She is an avid traveler and reader of nonfiction. Subscribe to this blog to learn more about technical writing, communicating, and machine learning within those domains.
Such a phrase from the seventies, right? Am I dating myself? Maybe, but hey, I was just a kid back then. I’m all grown-up now, and gaining insights by the day.
The goal of insights are, just as they were in the seventies, when everyone was seeing the original “analysts,” better decision-making. Not much has changed.
I take that back.
A whole lot has changed. We couldn’t have imagined, (or could we?) back when computations were done by punch-cards, that we’d no longer be shrink-wrapping user manuals, but instead looking to true trends analysis to see what our users want from our writing. Now, we are in the realm of truly seeking what patterns in our content are useful and what can go by the wayside, because we know, for instance, that our users no longer need to be told to enter their credentials upon login. They get it. They are familiar with creating passwords, and the concepts that were once totally unfamiliar are now second nature.
It’s a whole new frontier.
Now we are in a new domain.
Companies ask us not to be writers, actually, but content creators, content strategists. I used to scoff at that title, because anyone could use it. There is no credentialing: a licensed content strategist is a unicorn. And yet, real industries call for those who can produce (and produce well) two types of content: structured and unstructured. Yikes!
Structured content can be found. It has a home, a place, it is text-based in the case of email and office or web-based documentation. Unstructured content may include an archive of videos, or even non-text-based things like images and diagrams. There is a huge volume of this type of content, and yet it falls still under the purview of we, the content creators.
Those of us who used to be called “technical writers” or even “document specialists” or something like that find ourselves of course wrangling much more than documentation, doing much more than writing. So the issue became: how do we know if what we are doing works? Are we impacting our audience?
That’s where analysis comes into play and matters. Really, really matters.
Why spend hour upon hour creating a snazzy video or interactive tutorial if no one will watch or, dare I say, interact?
The whole goal of analytics is for us to know who is reading, watching, learning – and then we can improve upon what we’re building based on those engagements. It does little good to create a video training series, only to discover that users don’t have an internet connection on site to watch YouTube. Similarly, it’s not helpful to write detailed documentation and diagrams for users who prefer to watch 2-3 minute video step-throughs. It’s all about knowing one thing: audience. The essential element, always.
The central theme in Agile development, after all, was learning to understand the customer, so the essential element in designing better content, sensibly, ought to be the same thing. When we hunker down and learn what the customer really wants, we develop not just better software, but better content of all types.
With metrics on our side, our companies can identify just what content has real value, what has less, and what can really be dropped altogether. Historically, academic analysis was held to notions of things like how many times a subject blinked while reading an article. (Ho-hum.) Now, though, we can measure things like click-thhroughs, downloads, pauses during video, hover-helps, and more. How very, very cool.
Multiple screens to choose from. Photo credit: Alexandru Acea on Unsplash.
Historically, content analysis was slow, time-consuming, and it was a frustrating process with limited accuracy. Now, though, we can measure the usefulness of our content almost as fast as we can produce it. Content analytics are now available in a dizzying array of fields, reflecting a vast pool of data. The level of detail is phenomenal. For example, I’ll get feedback on this post within hours, if I want. I’ll create tags and labels to give me data that lets me know if I’ve reached the audience I want, whether I should pay for marketing, whether I might consider posting on social media channels, submitting to professional organizations, editing a bit, and so on. I may do all of those things or none of them. (Full disclosure: usually none, unless one of my kind colleagues points out a grievous error. I write for my own satisfaction and to sharpen my professional chops. Just sayin’)
Believe you me, the domain of conent analysis, in all areas, will grow and grow. Striking the perfect chord between efficiency and quality is not just on the horizon, it is in the room. AI-powered writing and editing, paired with the streamline of knowing we’ve reached the proper balance of placement and need – it’s not hyperbole to say the future is here. It’s just turning to my ‘analyst’ to ask whether I’ve written my content well enough and delivered it properly.
My product teams, my business unit, and my company are all grateful. And my work shows it.
I should probably start with a primer on Cognitive Bias before accusing anyone of allowing such biases to impact their release-note writing. That’s only fair.
Photo courtesy of Ryan Hafey on Unsplash.
In a nutshell, Cognitive Biases are those thinking patterns that result from the quick mental errors we make when relying on our own brains’ memories to make decisions. These biases arise when our brains try to simplify our very complex worlds. There are a few types of cognitive bias, too, not just one. There’s Self-serving bias, Confirmation bias, anchoring bias, hindsight bias, inattentional bias, and a handful more. It gets pretty complex in our brains, and we’re just trying to sort things out.
These biases are unconscious, meaning we don’t intend to apply them, and yet we do. The good news is, we can take steps to learn new ways of thinking, so as not to mess things up too badly with all of this brain bias. Whew, right?
Now that we’ve established a basic taxonomy, let’s dive in to how cognitive bias may (or may not) be creeping in to things like your technical writing. It’s not just in your release notes; that was just clickbait. But sure, bias can permeate your release notes and nearly any other part of your documentation. (Probably not code snippets, but I won’t split hairs.)
Writers and designers must recognize their own biases so that they can leave them behind when planning. Acknowledging sets of biases helps to shelve the impulse to draft documentation that is shaped by what they already know, assets they bring to the table, or assumptions they make about experience levels.
Let’s start with Self-serving bias. How might this little bug creep its way in to your otherwise beautiful and purposeful prose?
This bias is essentially when we attribute success to our own skills, but failures to outside factors. In our writing, this can appear when we imply that by default, software malfunctions are based in user error. Rather than allowing for a host of other factors, often our writing recommends checklist items that are user-centric rather than system-focused. While it’s true that there are countless ways that users can mess up our well-designed interfaces, there are likewise plenty of points of failure in our programs. Time to ‘fess up.
Confirmation bias can be just as damaging, wherein as writers we craft and process information that merely reinforces what we already believe to be true. While this approach is largely unintended, it often ignores inconsistency in our own writing. We tend to read and review our own documentation as though it is error-free, both from a process perspective and a grammatical-syntactical one. That’s just illogical. And yet, we persist. The need for collaborative peer-review is huge, as even the very best, most detail-oriented writers will make a typo that remains uncaught by grammar software. Humans are the only substitute, and always will be.
We write anchoring bias into our documentation all too often. This bias causes us, frail humans that we are, to rely mostly on the first information we are given, despite follow-up clarification. If we read first that a release was created by a team of ten, but then later learn that it is being developed by a team of seven, we are impressed by the team of seven because they are doing exceptional work. Now, it may be the case that when the ten-member team was working on it, three of them had very little to do. Yet, we anchor our thinking in the number ten, and set our expectations accordingly.
The notion that we “knew it all along” is the primary component of hindsight bias. We didn’t actually know anything, but somehow, we had a hunch, and if the hunch works out, then we confirm the heck out of it and say we saw it coming.
This can happen all too often when we revise our technical writing, jumping to an outcome we “saw coming,” which causes us to edit, overlook, or wipe out steps on the path to getting there. We sometimes become so familiar with the peccadilloes of some processes that we only selectively choose what information to include, and that’s a problem.
Inattentional bias is also known as inattentional “blindness,” and it’s a real doozy when it comes to technical writing, believe it or not. It is the basic failure to notice something that is otherwise fully visible, because you’re too focused on the task at hand. Sound familiar? Indeed. Our writing can get all sorts of messed up when we write a process document, say an installation guide, and don’t pause to note things that can go wrong, exceptions to the rule, and any number of tiny things that can (and indeed might) occur along the way. What to do when an error message pops up? What if login credentials are missing? System timeout? Sure, there are plenty of opportunities for us to drop these into our doc, and many times we do, but I saved this for last because – this will not surprise anyone who knows me – in order to overcome this particular bias, all you need do is become best buddies with your QA person. Legit. I recommend kicking the proverbial tires of your software alongside your QA buddy to see how often you get a “flag on the play.” That will grab you by the lapels and wake you up from the inattention, for real.
Your users will thank you if you learn, acknowledge, and overcome these biases when you write. Is it easy? Not really. Is it necessary? I’d say so. As my Carnegie Mellon mentor told me more than once, and I’ve lived by these words for my whole career: “Nothing is impossible; it just takes time.”
Take time with your writing, and you’ll soon be bias-free.
A conversation with a (junior) colleague this morning started off with “How did you decide to reformat your Best Practices Guide?” and moved on to things like “But how did you know that you should be working in Artificial Intelligence and VUI for this search stuff? I mean, how do you know it will work?”
I couldn’t help but chuckle to myself.
“Rest assured,” I said. “Part of it is just that you know what you know. Watch your customers. Rely on your gut. But more importantly, trust the data.” The response was something of a blank stare, which was telling.
All too often, tech writers – software writers especially it seems, although I do not have the requisite studies to support that claim – are too steeped in their actual products to reach out and engage in customer usage data, to mine engagement models and determine what their users want when it comes to their doc. They are focused on things, albeit important things, like grammar, standards, style guides, and so on. This leaves little time for customer engagement, so that falls to the bottom of the “to-do” list until an NPS score shows up and that score is abysmal. By that time, if the documentation set is large (like mine) it’s time for triage. But can the doc be saved? Maybe, maybe not.
If you’re lucky like I am, you work for a company that practices Agile or SAFe and you write doc in an environment that doesn’t shunt you to the end of the development line, so you can take a crack at fixing what’s broken. (If you don’t work for a rainbow-in-the-clouds company like mine, I suggest you dust off your resume and find one. They are super fun! But, I digress.)
Back to the colleague-conversation. Here’s how I knew to reformat the BP Guide that prompted the morning conversation:
I am working toward making all of my documentation consistent through the use of templating and accompanying videos. Why? Research.
According to Forrester, 79% of customers would rather use self-service documentation than a human-assisted support channel. According to an Aspect CX survey, 33% said they would rather “clean a toilet” than wait for Support. Seriously? Clean a toilet? That means I need to have some very user-friendly, easily accessible documentation that is clear, concise, and usable. My customers do NOT want to head over to support. It makes them angry. It’s squicky. They have very strong feelings about making support calls. I am not going to send my customers to support. The Acquity group says that 72% of customers buy only from vendors that can find product (support and documentation) content online. I want my customers’ experience to be smooth and easy. Super slick.
In retail sales, we already know that the day your product is offered on Amazon is the day you are no longer relevant in the traditional market so it’s a good thing that my company sells software by subscription and not washers and dryers. Companies that do not offer subscription models or create a top-notch customer experience cease to be relevant in a very short span of time thanks to thanks to changing interfaces.
I’m working to make the current customer support channel a fully automatable target. Why? It is low-risk, high-reward, and the right technology can automate the customer support representative out of a job. That’s not cruel or awful; it’s exciting, and it opens new opportunities. Think about the channels for new positions, new functions that support engineers. If the people who used to take support cal
ls instead now focus on designing smart user decision trees based on context and process tasks as contextual language designers, it’s a win. If former support analysts are in new roles as Voice of the Customer (VoC) Analysts, think about the huge gains in customer insights because they have the distinct ability to make deep analyses into our most valuable business questions rather than tackling mundane how-to questions and daily fixes that are instead handled by the deep learning of a smart VUI. It’s not magic; it’s today. These two new job titles are just two of the AI-based fields that are conjured by Joe McKendrick in a recent Forbes article so I am not alone in this thinking by far.
His research thinking aligns with mine. And Gartner predicts that by 2020, AI will create more jobs than it eliminates.
So as I nest these Best Practices guides, as I create more integrated documentation, as I rely on both my gut and my data, I know where my documentation is headed, because I rely on data. I look to what my customers tell me. I dive into charts and graphs and points on scales. The information is there, and AI will tell me more than I ever dreamed of…if I listen closely and follow the learning path.








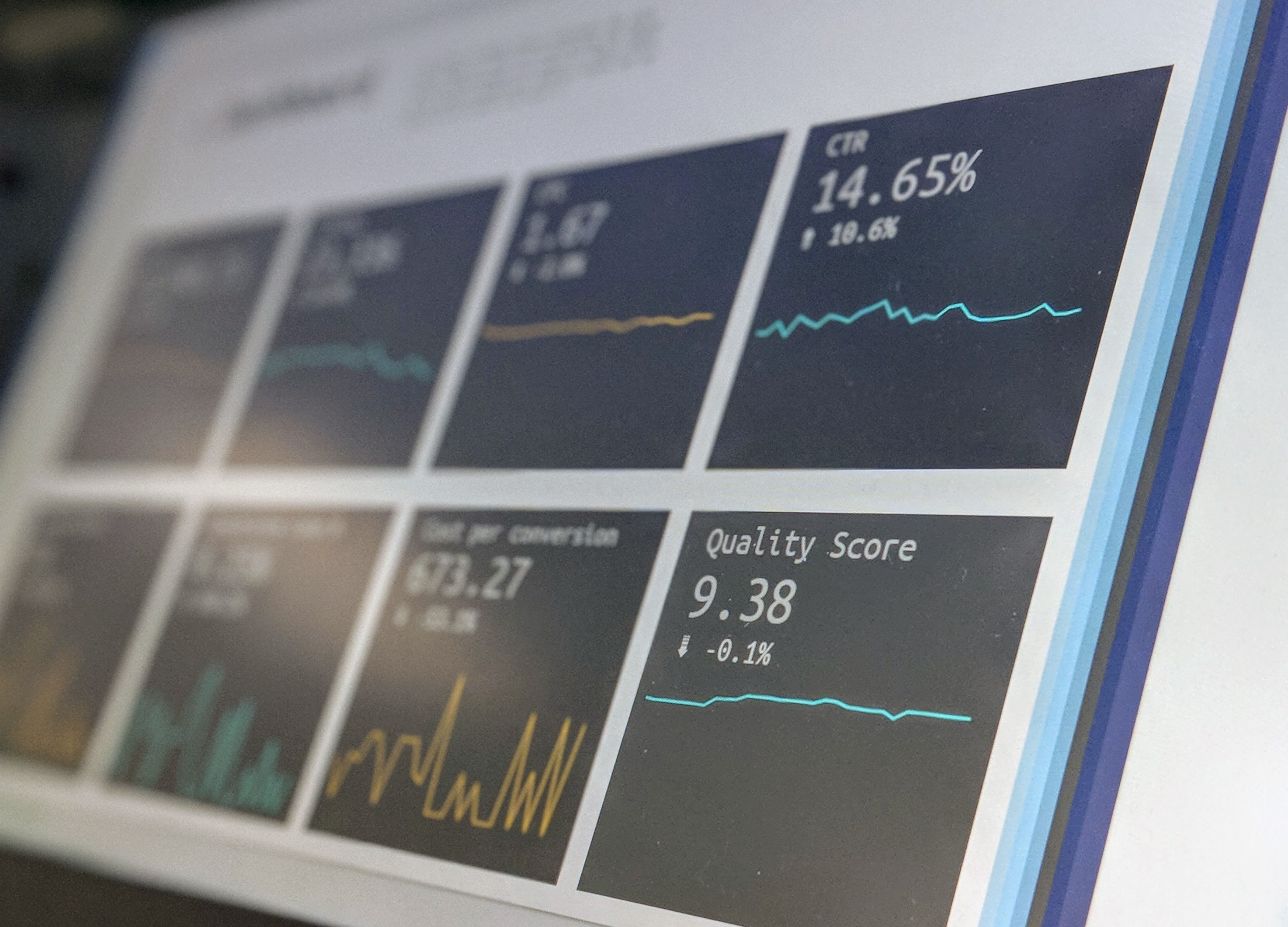



 A conversation with a (junior) colleague this morning started off with “How did you decide to reformat your Best Practices Guide?” and moved on to things like “But how did you know that you should be working in Artificial Intelligence and VUI for this search stuff? I mean, how do you know it will work?”
A conversation with a (junior) colleague this morning started off with “How did you decide to reformat your Best Practices Guide?” and moved on to things like “But how did you know that you should be working in Artificial Intelligence and VUI for this search stuff? I mean, how do you know it will work?” According to Forrester, 79% of customers would rather use self-service documentation than a human-assisted support channel. According to an Aspect CX survey, 33% said they would rather “clean a toilet” than wait for Support. Seriously? Clean a toilet? That means I need to have some very user-friendly, easily accessible documentation that is clear, concise, and usable. My customers do NOT want to head over to support. It makes them angry. It’s squicky. They have very strong feelings about making support calls. I am not going to send my customers to support. The Acquity group says that 72% of customers buy only from vendors that can find product (support and documentation) content online. I want my customers’ experience to be smooth and easy. Super slick.
According to Forrester, 79% of customers would rather use self-service documentation than a human-assisted support channel. According to an Aspect CX survey, 33% said they would rather “clean a toilet” than wait for Support. Seriously? Clean a toilet? That means I need to have some very user-friendly, easily accessible documentation that is clear, concise, and usable. My customers do NOT want to head over to support. It makes them angry. It’s squicky. They have very strong feelings about making support calls. I am not going to send my customers to support. The Acquity group says that 72% of customers buy only from vendors that can find product (support and documentation) content online. I want my customers’ experience to be smooth and easy. Super slick.

